


BIP: 152
Layer: Peer Services
Title: Compact Block Relay
Author: Matt Corallo <bip152@bluematt.me>
Comments-Summary: Unanimously Recommended for implementation
Comments-URI: https://github.com/bitcoin/bips/wiki/Comments:BIP-0152
Status: Final
Type: Standards Track
Created: 2016-04-27
License: PD
Compact blocks on the wire as a way to save bandwidth for nodes on the P2P network.
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in RFC 2119.
Historically, the Bitcoin P2P protocol has not been very bandwidth efficient for block relay. Every transaction in a block is included when relayed, even though a large number of the transactions in a given block are already available to nodes before the block is relayed. This causes moderate inbound bandwidth spikes for nodes when receiving blocks, but can cause very significant outbound bandwidth spikes for some nodes which receive a block before their peers. When such spikes occur, buffer bloat can make consumer-grade internet connections temporarily unusable, and can delay the relay of blocks to remote peers who may choose to wait instead of redundantly requesting the same block from other, less congested, peers.
Thus, decreasing the bandwidth used during block relay is very useful for many individuals running nodes.
While the goal of this work is explicitly not to reduce block transfer latency, it does, as a side effect reduce block transfer latencies in some rather significant ways. Additionally, this work forms a foundation for future work explicitly targeting low-latency block transfer.
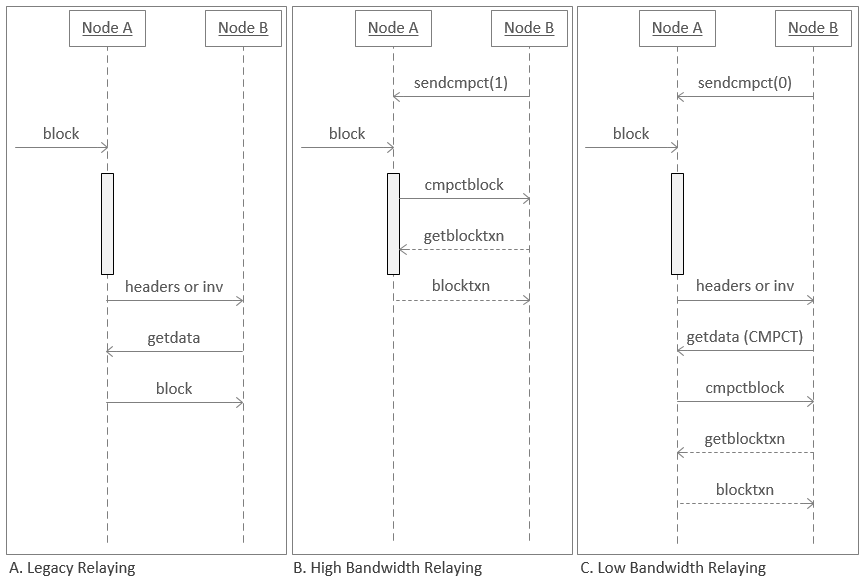
The protocol is intended to be used in two ways, depending on the peers and bandwidth available, as discussed later. The “high-bandwidth” mode, which nodes may only enable for a few of their peers, is enabled by setting the first boolean to 1 in a sendcmpct message. In this mode, peers send new block announcements with the short transaction IDs already (via a cmpctblock message), possibly even before fully validating the block (as indicated by the grey box in the image above). In some cases no further round-trip is needed, and the receiver can reconstruct the block and process it as usual immediately. When some transactions were not available from local sources (ie mempool), a getblocktxn/blocktxn roundtrip is necessary, bringing the best-case latency to the same 1.5*RTT minimum time that nodes take today, though with significantly less bandwidth usage.
The “low-bandwidth” mode is enabled by setting the first boolean to 0 in a sendcmpct message. In this mode, peers send new block announcements with the usual inv/headers announcements (as per BIP130, and after fully validating the block). The receiving peer may then request the block using a MSG_CMPCT_BLOCK getdata request, which will receive a response of the header and short transaction IDs. In some cases no further round-trip is needed, and the receiver can reconstruct the block and process it as usual, taking the same 1.5RTT minimum time that nodes take today, though with significantly less bandwidth usage. When some transactions were not available from local sources (ie mempool), a getblocktxn/blocktxn roundtrip is necessary, bringing the latency to at least 2.5RTT in this case, again with significantly less bandwidth usage than today. Because TCP often exhibits worse transfer latency for larger data sizes (as a multiple of RTT), total latency is expected to be reduced even when the full 2.5*RTT transfer mechanism is used.
Several new data structures are added to the P2P network to relay compact blocks: PrefilledTransaction, HeaderAndShortIDs, BlockTransactionsRequest, and BlockTransactions.
For the purposes of this section, CompactSize refers to the variable-length integer encoding used across the existing P2P protocol to encode array lengths, among other things, in 1, 3, 5 or 9 bytes. Only CompactSize encodings which are minimally-encoded (ie the shortest length possible) are used by this spec. Any other CompactSize encodings are left with undefined behavior.
Several uses of CompactSize below are “differentially encoded”. For these, instead of using raw indexes, the number encoded is the difference between the current index and the previous index, minus one. For example, a first index of 0 implies a real index of 0, a second index of 0 thereafter refers to a real index of 1, etc.
A PrefilledTransaction structure is used in HeaderAndShortIDs to provide a list of a few transactions explicitly.
| Field Name | Type | Size | Encoding | Purpose |
|---|---|---|---|---|
| index | CompactSize | 1, 3 bytes | Compact Size, differentially encoded since the last PrefilledTransaction in a list | The index into the block at which this transaction is |
| tx | Transaction | variable | As encoded in “tx” messages sent in response to getdata MSG_TX | The transaction which is in the block at index index. |
A HeaderAndShortIDs structure is used to relay a block header, the short transactions IDs used for matching already-available transactions, and a select few transactions which we expect a peer may be missing.
| Field Name | Type | Size | Encoding | Purpose |
|---|---|---|---|---|
| header | Block header | 80 bytes | First 80 bytes of the block as defined by the encoding used by “block” messages | The header of the block being provided |
| nonce | uint64_t | 8 bytes | Little Endian | A nonce for use in short transaction ID calculations |
| shortids_length | CompactSize | 1 or 3 bytes | As used to encode array lengths elsewhere | The number of short transaction IDs in shortids (ie block tx count - prefilledtxn_length) |
| shortids | List of 6-byte integers | 6*shortids_length bytes | Little Endian | The short transaction IDs calculated from the transactions which were not provided explicitly in prefilledtxn |
| prefilledtxn_length | CompactSize | 1 or 3 bytes | As used to encode array lengths elsewhere | The number of prefilled transactions in prefilledtxn (ie block tx count - shortids_length) |
| prefilledtxn | List of PrefilledTransactions | variable size*prefilledtxn_length | As defined by PrefilledTransaction definition, above | Used to provide the coinbase transaction and a select few which we expect a peer may be missing |
A BlockTransactionsRequest structure is used to list transaction indexes in a block being requested.
| Field Name | Type | Size | Encoding | Purpose |
|---|---|---|---|---|
| blockhash | Binary blob | 32 bytes | The output from a double-SHA256 of the block header, as used elsewhere | The blockhash of the block which the transactions being requested are in |
| indexes_length | CompactSize | 1 or 3 bytes | As used to encode array lengths elsewhere | The number of transactions being requested |
| indexes | List of CompactSizes | 1 or 3 bytes*indexes_length | Differentially encoded | The indexes of the transactions being requested in the block |
A BlockTransactions structure is used to provide some of the transactions in a block, as requested.
| Field Name | Type | Size | Encoding | Purpose |
|---|---|---|---|---|
| blockhash | Binary blob | 32 bytes | The output from a double-SHA256 of the block header, as used elsewhere | The blockhash of the block which the transactions being provided are in |
| transactions_length | CompactSize | 1 or 3 bytes | As used to encode array lengths elsewhere | The number of transactions provided |
| transactions | List of Transactions | variable | As encoded in “tx” messages in response to getdata MSG_TX | The transactions provided |
Short transaction IDs are used to represent a transaction without sending a full 256-bit hash. They are calculated by:
A new inv type (MSG_CMPCT_BLOCK == 4) and several new protocol messages are added: sendcmpct, cmpctblock, getblocktxn, and blocktxn.
NOTE: Segregated witness is not supported in Bitcoin Cash and therefore does not support this definition of Compact Blocks version 2.
The following is left solely for historical purposes.
Compact blocks version 2 is almost identical to version 1, but supports segregated witness transactions (BIP 141 and BIP 144). The changes are:
For nodes which have sufficient inbound bandwidth, sending a sendcmpct message with the first integer set to 1 to up to 3 peers is RECOMMENDED. If possible, it is RECOMMENDED that those peers be selected based on their past performance in providing blocks quickly (eg the three peers which provided the highest number of the recent N blocks the quickest), allowing nodes to receive blocks which come from those peers in only 0.5*RTT.
Nodes MUST NOT send such sendcmpct messages to more than three peers, as it encourages wasting outbound bandwidth across the network.
All nodes SHOULD send a sendcmpct message to all appropriate peers. This will reduce their outbound bandwidth usage by allowing their peers to request compact blocks instead of full blocks.
Nodes with limited inbound bandwidth SHOULD request blocks using MSG_CMPCT_BLOCK/getblocktxn requests, when possible. While this increases worst-case message round-trips, it is expected to reduce overall transfer latency as TCP is more likely to exhibit poor throughput on low-bandwidth nodes.
Nodes sending cmpctblock messages SHOULD limit prefilledtxn to 10KB of transactions. When in doubt, nodes SHOULD only include the coinbase transaction in prefilledtxn.
Nodes MAY pick one nonce per block they wish to send, and only build a cmpctblock message once for all peers which they wish to send a given block to. Nodes SHOULD NOT use the same nonce across multiple different blocks.
Nodes MAY impose additional requirements on when they announce new blocks by sending cmpctblock messages. For example, nodes with limited outbound bandwidth MAY choose to announce new blocks using inv/header messages (as per BIP130) to conserve outbound bandwidth.
Note that the MSG_CMPCT_BLOCK section does not require that nodes respond to MSG_CMPCT_BLOCK getdata requests for blocks which they did not recently announce. This allows nodes to calculate cmpctblock messages at announce-time instead of at request-time. Blocks which are requested with a MSG_CMPCT_BLOCK getdata, but which are not responded to with a cmpctblock message MUST be responded to with a block message, allowing nodes to request all blocks using MSG_CMPCT_BLOCK getdatas and rely on their peer to pick an appropriate response.
While the current version sends transactions with the same encodings as are used in tx messages and elsewhere in the protocol, the version field in sendcmpct is intended to allow this to change in the future. For this reason, it is recommended that the code used to decode PrefilledTransaction and BlockTransactions messages be prepared to take a different transaction encoding, if and when the version field in sendcmpct changes in a future BIP.
Any undefined behavior in this spec may cause failure to transfer block to, peer disconnection by, or self-destruction by the receiving node. A node receiving non-minimally-encoded CompactSize encodings should make a best-effort to eat the sender’s cat.
As high-bandwidth mode permits relaying of CMPCTBLOCK messages prior to full validation (requiring only that the block header is valid before relay), nodes SHOULD NOT ban a peer for announcing a new block with a CMPCTBLOCK message that is invalid, but has a valid header. For avoidance of doubt, nodes SHOULD bump their peer-to-peer protocol version to 70015 or higher to signal that they will not ban or punish a peer for announcing compact blocks prior to full validation, and nodes SHOULD NOT announce a CMPCTBLOCK to a peer with a version number below 70015 before fully validating the block.
SPV nodes which implement this spec must consider the implications of accepting blocks which were not validated by the node which provided them. Especially SPV nodes which allow users to select a “trusted full node” to sync from may wish to avoid implementing this spec in high-bandwidth mode.
Note that this spec does not change the requirement that nodes only relay information about blocks which they have fully validated in response to GETDATA/GETHEADERS/GETBLOCKS/etc requests. Nodes which announce using CMPCTBLOCK message and then receive a request for associated block data SHOULD ensure that messages do not go unresponded to, and that the appropriate data is provided after the block has been validated, subject to standard message-response ordering requirements. Note that no requirement is added that the node respond to the request with the new block included in eg GETHEADERS or GETBLOCKS messages, but the node SHOULD re-announce the block using the associated announcement methods after validation has completed if it is not included in the original response. On the other hand, nodes SHOULD delay responding to GETDATA requests for the block until validation has completed, stalling all message processing for the associated peer. REJECT messages are not considered “responses” for the purpose of this section.
As a result of the above requirements, implementors may wish to consider the potential for the introduction of delays in responses while remote peers validate blocks, avoiding delay-causing requests where possible.
There have been many proposals to save wire bytes when relaying blocks. Many of them have a two-fold goal of reducing block relay time and thus rely on the use of significant processing power in order to avoid introducing additional worst-case RTTs. Because this work is not focused primarily on reducing block relay time, its design is much simpler (ie does not rely on set reconciliation protocols). Still, in testing at the time of writing, nodes are able to relay blocks without the extra getblocktxn/blocktxn RTT around 90% of the time. With a smart compact-block-announcement policy, it is thus expected that this work might allow blocks to be relayed between nodes in 0.5RTT instead of 1.5RTT at least 75% of the time.
There are several design goals for the Short ID calculation:
SipHash is a secure, fast, and simple 64-bit MAC designed for network traffic authentication and collision-resistant hash tables. We truncate the output from SipHash-2-4 to 48 bits (see next section) in order to minimize space. The resulting 48-bit hash is certainly not large enough to avoid intentionally created individual collisons, but by using the block hash as a key to SipHash, an attacker cannot predict what keys will be used once their transactions are actually included in a relayed block. We mix in a per-connection 64-bit nonce to obtain independent short IDs on every connection, so that even block creators cannot control where collisions occur, and random collisions only ever affect a small number of connections at any given time. The mixing is done using SHA256(block_header || nonce), which is slow compared to SipHash, but only done once per block. It also adds the ability for nodes to choose the nonce in a better than random way to minimize collisions, though that is not necessary for correct behaviour. Conversely, nodes can also abuse this ability to increase their ability to introduce collisions in the blocks they relay themselves. However, they can already cause more problems by simply refusing to relay blocks. That is inevitable, and this design only seeks to prevent network-wide misbehavior.
Thanks to the block-header-based SipHash keys, we can assume that the only collisions on links between honest nodes are random ones.
For each of the t block transactions, the receiver will compare its received short ID with that of a set of m mempool transactions. We assume that each of those t has a chance r to be included in that set of m. If we use B bits short IDs, for each comparison between a received short ID and a mempool transaction, there is a chance of P = 1 - 1 / 2^B that a mismatch is detected as such.
When comparing a given block transaction to the whole set of mempool transactions, there are 5 cases to distinguish:
r * P^(m - 1).(1 - r) * P^m.r * (1 - P^(m - 1)).(1 - r) * (1 - P^m - m * (1 - P) * P^(m - 1)).(1 - r) * m * (1 - P) * P^(m - 1).(note that these 5 numbers always add up to 100%)
In case 1, we’re good. In cases 2, 3, or 4, we request the full transaction because we know we’re uncertain. Only in case 5, we fail to reconstruct. The chance that case 5 does not occur in any of the t transactions in a block is (1 - (1 - r) * m * (1 - P) * P^(m - 1))^t. This expression is well approximated by 1 - (1 - r) * m * (1 - P) * t = 1 - (1 - r) * m * t / 2^B. Thus, if we want only one in F block transmissions between honest nodes to fail under the conservative r = 0 assumption, we need log2(F * m * t) bits hash functions.
This means that B = 48 bits short IDs suffice for blocks with up to t = 10000 transactions, mempools up to m = 100000 transactions, with failure to reconstruct at most one in F = 281474 blocks. Since failure to reconstruct just means we fall back to normal inv/header based relay, it isn’t necessary to avoid such failure completely. It just needs to be sufficiently rare they have a lower impact than random transmission failures (for example, network disconnection, node overloaded, …).
The changes to transaction and block relay in BIP 144 introduce separate MSG_FILTERED_ versions of messages in getdata,
allowing a receiver to choose individually where witness data is wanted.
This method is not useful for compact blocks because cmpctblock blocks can be sent unsolicitedly in high-bandwidth
mode, so we need to negotiate at least whether those should include witness data up front. There is little use for a
validating node that only sometimes processes witness data, so we may as well use that negotiation for everything and
turn it into a separate protocol version. We also need a means to distinguish different versions of the same transaction
with different witnesses for correct reconstruction, so this also forces us to use wtxids instead of txids for short IDs
everywhere in that case.
Older clients remain fully compatible and interoperable after this change.
https://github.com/bitcoin/bitcoin/pull/8068 for version 1.
https://github.com/bitcoin/bitcoin/pull/8393 for version 2.
Thanks to Gregory Maxwell for the initial suggestion as well as a lot of back-and-forth design and significant testing.
Thanks to Nicolas Dorier for the protocol flow diagram.
This document is placed in the public domain.