This article describes a technique where untrusted nodes can safely provide meta-data about transactions and blocks to other nodes as part of the INV protocol. This is essential to prevent DOS attacks by allowing nodes to reject transactions that do not match the node’s fee policy without actually executing the transaction’s scripts. Preventing this type of DOS will allow a blockchain to enable much more sophisticated and complex scripts without resorting to techniques like Ethereum’s “gas”.
It would be very useful for a node to have reliable data on properties of blockchain objects — blocks and transactions — before evaluating or requesting an object. The advantage is clear — a node can reject an object before validation or download, based on whether the advertised properties match the node’s policies. For example, is a transaction’s fee large enough given its size and sigops?
Previous proposals in this area have suggested including block size in the block header to form a proof-of-work protected commitment to this data. The advantage is simple — a node can know the size of a block, and apply its max block size policy, before requesting the block. This blocks the download-an-infinite-sized-block attack.
Let’s create a new concept called an “object property commitment” formed by hashing the concatenation of an object and meta-data describing some properties of that object. In our example, if the block header contained the block size, the hash would be an object property commitment. Since blocks are secured by proof-of-work, the contained meta-data would be similarly secured.
A proof-of-work secured object property commitment has a very strong security model since an invalid property will cause the creator to lose the energy required to calculate the proof-of-work. However, there are problems with this approach:
It turns out that we do not need proof-of-work to secure object property commitments — the advantages of object property commitments can be achieved at the peer-2-peer (P2P) messaging layer. But it’s not perfect, when implemented at the P2P layer, a dishonest node can trick another node exactly once into consuming no more than the resources required to validate the claimed property commitment. This is OK, within Bitcoin Cash, validation of blocks and transactions up to a reasonable limit in properties such as size and number of sigops is not much work. Finally, to head of confusion, it should be emphasized that this system still requires validation of blocks and transactions accepted by the node. This proposal is not changing the full node security model.
P2P messages use the object property commitment (OPC) rather than an object’s hash for all announcement and request messages. This means that if a node lies about the properties of an object, this “lying” notification has a different OPC then the “honest” notification. To the target node, these two OPCs look like completely different objects.
A misbehaving node can execute a few attacks:
If you understand the above and can see how we can obviously apply this to both blocks and transactions, then no reason to read on — it may seem repetitive. But if you are interested, next I will go over specific details.
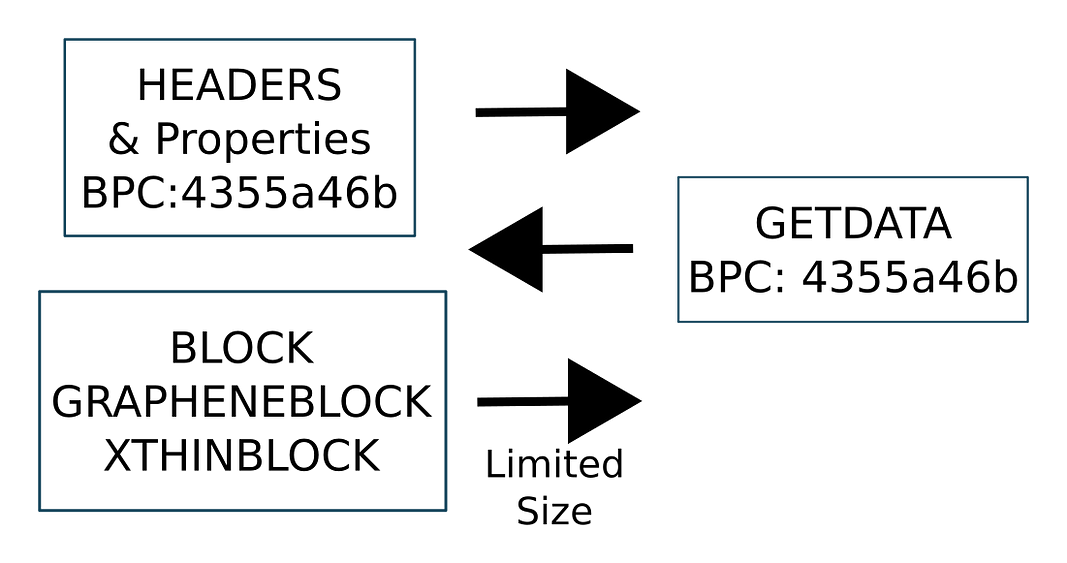
Block header messages are extended to include block properties including the size in bytes, the number of transactions, the number of executed sigops, and the number of output sigops. This data is hashed to form a Block Property Commitment (BPC). Different BPCs are tracked as separate entities even if they reference the same block. This effectively looks like a transient fork in the header tree, similar to that of a temporary blockchain fork caused by a mining tie (except that no mining resources are wasted).
Nodes will announce and request headers by OPC. When the OPC is validated, it can check the properties and choose to discard the header or request download of the block.
A dishonest node can make the following actions:
Note that if honest nodes typically outnumber dishonest nodes, a node can also track the number of nodes announcing one BPC vs another for a particular block header, and download the most announced BPC first. This will tend to ignore dishonest nodes, yet gracefully degrades into less efficient but still correct behavior in the case where dishonest nodes outnumber honest ones.
Bitcoin family cryptocurrencies currently use the currency’s scripting capabilities in very minor ways. Most scripts are just a few opcodes long and follow a handful of well-known templates. There are two problems with enabling longer and more interesting scripting. First, there are consensus rules limiting certain script properties — number of executed instructions, script length, and number of sigops. Second, miners need to be able to reject a transaction that has insufficient fees relative to resources consumed before actually evaluating the transaction (and consuming those CPU/RAM resources). Since opcodes consume very different CPU and RAM resources (and may not even be executed if inside a conditional clause) a node cannot determine whether a transaction’s script execution meets some resource utilization criteria until after it is executed. This offers an attack vector where the node must waste resources to evaluate a script that it will subsequently reject due to insufficient fee. Since the transaction’s fee is not spent, this attack is almost free for the attacker, meaning that the fee evaluation needs to be almost free for the evaluator. This is one reason why fee evaluation is currently based only on transaction size.
Solving this second problem — a-priori determination of resource consumption — would allow fine grained consensus limits, which in turn means that the broad consensus limits (like on number of instructions executed) could be dramatically raised because transactions would generally be rejected before evaluation due to the breaking of a detailed consensus limit (such as sigops executed) or due to insufficient fees paid.
First, note that transactions are always advertised to other nodes after validation so the sender contains the information that the receiver would like to have. This is true recursively to the source of the transaction, which has evaluated the scripts in the process of forming the transaction (note, it is not strictly necessary for the originator to evaluate the scripts — if the prevout and the scriptSig “solution” follow known templates, the originator may know the properties of these templates without evaluation) .
Today, transactions are announced to nodes via INV messages that contain type and hash (transaction id) fields. Instead, the transaction and properties (fee, sigop counts, hash counts, and any other expensive opcode counts for example) are hashed to form a transaction property commitment (TPC). The TPC is placed into an INV message using a new type and announced to all connected nodes. Nodes respond with a GETDATA request, and the GETDATA reply returns the transaction and properties (all data required to calculate the TPC) via a new TXP message. These properties are then used to reject the transaction, or accept it into processing.
There are several possible dishonest behaviors.
In all cases dishonest nodes are detected and banned, and propagation of the transaction cannot be blocked (provided one honest node exists).
The following properties would be valuable to know about a transaction:
CPU resource use:
Memory use:
Other properties, such as transaction size and fee, would be useful but are quickly calculable from the transaction object. However if an transaction’s properties are provided before the transaction itself (as part of an INV, for example) they should be included.
There is a tradeoff between supplying object properties as part of an entity announcement message (INV) and supplying them with the object. The former would allow a node to reject a transaction without downloading it, but the cost is receiving multiple copies of the object properties as every connected node sends this node an INV. Note also a 3 step protocol could be designed that starts with a plain INV, moves to object properties, and finally the requests the full object. Although this minimizes bandwidth, this multi-step conversation increases latency.
Without considering the merit of this approach (since it will vary based on the object), these architectures can be accomplished with a small modification to the proposal.
To include object properties inside an INV, the TPC will be calculated from the object hash (transaction id in this case) and properties, rather than the full object. Next, the INV that is sent does not contain the TPC, but its pre-image — the object hash and properties. The receiving node can then examine the properties, and calculate the TPC from them. It still must request and internally track the object by TPC for the same reasons as described above (to defeat dishonest nodes). When the sending node receives a GETDATA request for the TPC, it only needs to send the transaction (since the receiver already has the properties).
The 3 step protocol is an obvious blend of the two already discussed so will not be addressed further.