


Andrew Stone. Sep 19, 2017
Use references based on blockchain height and transaction offset rather than hash to dramatically reduce the size of this data
Transaction inputs are specified by a data structure called an ‘outpoint’ that contains the sha256 hash of a prior transaction and an index specifying the output (vout). This requires 32 bytes for the hash and 4 bytes for the index (although the “CompactInt” type would be a natural choice, it looks like the index is written as a 32 bit unsigned integer).
A lot of bandwidth and disk space is consumed holding these references. And the hashes are inherently incompressible — if they were distinguishable from random data that would hint at hash function cryptographic insecurity. They appear exactly once in the blockchain per output (when the transaction’s output is spent) so repetition (and the resultant compression opportunities) is minimal.
The purpose of a transaction hash is to be a globally unique pointer to a transaction. But once a transaction is added into the blockchain, we have another globally unique means to reference it — by block height and transaction index. And so unspent outputs can be referenced by a triple, block height, transaction index, and vout index. Let us call this a “chainref”. It serves the same purpose as an outpoint, yet does so by referencing a position in the blockchain rather than by using a hash.
Let us propose an unambiguous chainref format (block height: compact int, transaction: compact int, vout: compact int). But can we use even fewer bytes for network and disk chainref representations?
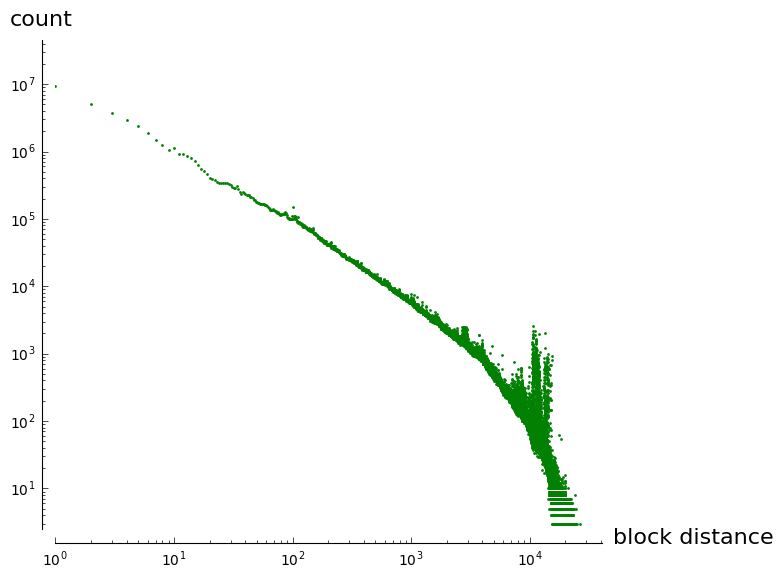
This is a plot of spending age for every transaction in blocks 0–367104, note the log-log scale.

Here is the same plot focusing on just the the number of inputs that refer to the prior 100 blocks:
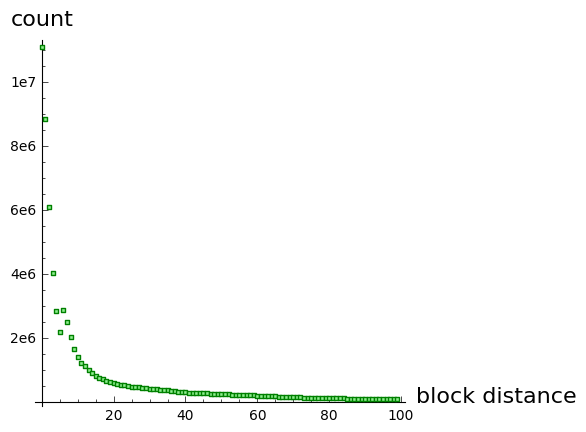
Transactions are more likely to be spent sooner than later. So let’s propose a block encoding for network traffic that is an offset from the current block and consumes 8 bits. The receiver knows our current block due to block header announcements, and since these announcements and the transactions announcements are ordered as they traverse the network the receiver always knows exactly what block height the sender is on. However, following the robustness principle, if the receiver receives an “invalid” transaction, it can guess that the sender might be off-by-one and simply check that possibility.
The block encoding for on-disk transactions is similar but starts from the block that contains the transaction.
By analyzing blocks 0 to 367104 it turns out that 67% of transaction inputs can encode a prior block reference in 1 byte and 99% in 2 bytes. Blocks typically contain a few thousand transactions per MB, so more than 8 bits. But 16 bits or 65k transactions is a lot. and most transactions have few outputs, so let’s steal 2 bits from the transaction index and use it for the vout. So the entire chainref can be typically encoded in (8 or 16, 14, and 2) bits or 3 or 4 bytes. This will work for a few years, but we can also include a format that devotes 20 bits to the transaction index and 4 bits to the output that will work up to about 350MB blocks and consume 4 to 5 bytes.
But today we can compress the 36 byte outpoint into a 3 or 4 byte chainref giving us between 92% and 89% savings. Since outpoints comprise about 17% of the data in a block, this corresponds to ondisk blockchain savings of 15% percent.
We would achieve similar, but slightly worse savings in network transfer, because we would not be able to use chainrefs for transactions that refer to uncommitted transactions.
[Nov 22, 2020 note]
However, we could use “short hashes” (a random selection of bits in the hash) to refer to these transactions.
Also note that a chainref could be used to communicate the script portion of a transaction output if it is reused.
Implementation
These savings can be implemented in the network protocol relatively easily. A new services bit can be used to indicate chainref support, and then senders can provide outpoints or chainrefs at their discretion in the GETDATA response.
Receivers need to translate the chainref into an outpoint before running signature validation. This could be done easily (but slowly) by accessing the block database, but the best choice would be to enhance the UTXO set with chainref indexes.
But essentially, all elements of the bitcoin network can be beneficially switched to specifying the transaction using chainrefs, using the transaction hash only for signature validation and for referring to uncommitted transactions.
Blocks written to disk using chainrefs rather than outpoints, actually makes the disk data more useful — it makes it easy to trace coins backwards through time. In contrast, today this functionality is not available on the standard client, and on enhanced clients a separate “txindex” data structure needs to be maintained that maps transaction hashes to block, index pairs. But changing the on disk structure is a larger change than changing the network protocol, because existing nodes either need to rewrite their blockchain data or allow a hybrid of both on-disk formats. And this means that the on-disk data would be incompatible with clients that do not implement chainrefs.
Hard Fork?
Could transaction data “natively” use chainrefs rather than outpoints? This would require a hard fork since its a change to the signed transaction format, yet would eliminate translation between chainref and outpoint at signature verification. One huge advantage of this format around fraud proofs: light clients (clients that do not contain the entire blockchain) can very easily be shown proof that a transaction has nonexistent inputs. If the chainref refers to a beyond-the-block-end transaction, the prover simply provides the merkle proof of the last transaction in the block. If the chainref refers to a real location but the transaction uses an incorrect utxo, the prover provides the merkle proof and real transaction (and utxo) at that location.
In contrast, with the outpoint format, proving that a parent transaction does NOT exist in the blockchain requires the entire blockchain (see https://gist.github.com/justusranvier/451616fa4697b5f25f60).
This would require a hard fork since its a change to the signed transaction data format. And the outpoint format would need to still be supported to handle uncommitted transactions. So transactions could contain a hybrid of chainrefs and outpoints.
One interesting question in this case is whether a chain reorg could cause the wrong previous output to be spent. This is not possible since the signature would no longer validate, unless the transaction in the old block has the same signature as the one in the new block. The only way this could happen is if the transaction is malleable, or for “give-away” transactions like anyone-can-spend.
Another issue is that a chain reorg could cause transactions to become invalid, if the transaction it refers to changes. This would have a pretty large negative effect on accepting 0-conf transactions. I think it is onerous to force the vendor to evaluate the risk of 0-conf transactions with recent parents differently than other 0-conf transactions. A reasonable approach would be to only use chainrefs if the parent transaction is a few blocks deep (let’s say 10 blocks), and (so solve the fraud proof problem for outpoints), have miners include the block height for any included outpoints as described in Justus Ranvier’s fraud proof paper.
It makes a lot of sense to start referring to committed transactions by chainref and to modify Bitcoin clients to use chainrefs in network protocols and disk formats. Doing so will reduce network bandwidth and disk storage requirements by about 15%. However, it does not make sense to eliminate the transaction hash altogether. We still need transaction hashes to refer to uncommitted transactions, and to create spend chains of uncommitted transactions. Whether chainrefs should be added into the signed transaction as an additional way to specify parent transactions is an open question. Such a change requires a hard fork, and the benefits are marginal because we must still preserve the outpoint format to create chains of unconfirmed transactions.
Special thanks to Andrea Suisani